Reconnaissance automatique de texte
(HTR/OCR)
Qu'est-ce que la reconnaissance automatique de texte ?
La reconnaissance automatique de texte (ATR - Automatic Text Recognition) transforme vos piles de documents papier en un format numérique modifiable et exploitable par des ordinateurs.
Qu'est-ce que la reconnaissance optique de caractères (OCR) ?
L'OCR (reconnaissance optique de caractères) est la méthode traditionnelle de reconnaissance de texte imprimé : elle analyse la forme de chaque caractère et la compare à des polices d'écriture enregistrées. Elle fonctionne bien lorsque les caractères sont clairement séparés, que les polices sont standard et que la qualité de l'image est bonne. Dans le cas contraire, la précision diminue rapidement.
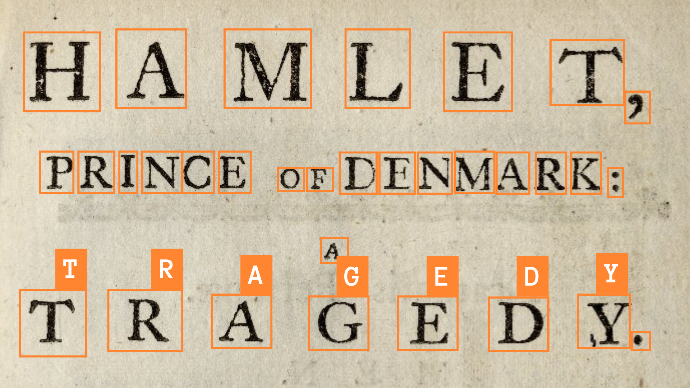
Qu'est-ce que la reconnaissance de texte manuscrit (HTR) ?
La HTR (reconnaissance de texte manuscrit) est conçue pour reconnaître le texte manuscrit. Contrairement à l'OCR, la HTR utilise des modèles qui prennent en compte des mots ou des lignes de texte entiers, combinant des informations optiques et le contexte linguistique pour produire des transcriptions plus cohérentes.

Qu'en est-il de la reconnaissance automatique de texte (ATR) ?
L'ATR est la convergence des technologies OCR et HTR. Au cours de la dernière décennie, avec le développement des algorithmes d'apprentissage profond, les frontières entre l'OCR pour les documents imprimés et l'HTR pour les documents manuscrits s'estompent. Les modèles d'ATR reconnaissent à la fois le texte imprimé et manuscrit et traitent des lignes ou des paragraphes.

Nos capacités de traitement ATR
Transcription multiligne
Texte mixte manuscrit et imprimé
Tous types d'écriture (latine, arabe, cyrillique...)
Écriture manuscrite historique et contemporaine
Langues anciennes
Enrichissement avec des métadonnées
La méthodologie ATR unique de TEKLIA
Nos services de reconnaissance automatique de texte (ATR) s'appuient sur les dernières avancées en matière de technologies d'apprentissage profond. Nous formons des modèles entièrement personnalisés, conçus pour comprendre et transcrire avec précision les langues rares et les écritures manuscrites complexes. TEKLIA a développé deux approches différentes pour le traitement ATR des documents historiques :
Méthode ATR séquentielle
Méthode ATR intégrée
Dans des scénarios plus complexes où la mise en page ne correspond pas à une structure standard, il peut être impossible de déterminer un ordre de lecture évident pour l'ensemble de la page. Dans de tels cas, TEKLIA propose une approche intégrée de bout en bout utilisant un seul modèle d'apprentissage profond. L'apprentissage du modèle est basé sur les modèles et les structures présents dans les données d'entraînement, ce qui lui permet de déterminer avec précision l'ordre de lecture des zones de texte, même dans des mises en page complexes et variées.
Questions-réponses : Spécificités du document
Détection des lignes de texte dans n'importe quelle orientation :
Nos modèles de reconnaissance de lignes de texte (Doc-UFCN , YOLO V8) sont capables de détecter les lignes de texte dans n'importe quelle orientation (0 à 360°). Ces modèles sont conçus pour détecter avec précision les lignes de texte, quelle que soit leur position de rotation.
De plus, les modèles intégrés tels que le Document Attention Network (DAN) ont la capacité de prédire la langue en même temps que la transcription du texte, ce qui améliore l'efficacité et la précision du traitement des documents multilingues. Nous expérimentons actuellement le DAN pour reconnaître des documents contenant des langues écrites dans des directions différentes (français et arabe).
Questions-réponses : Contrôle de qualité
Arkindex for Exploration : Arkindex est notre premier outil conçu pour visualiser les résultats de la transcription automatique et les comparer avec les images correspondantes. Il permet aux utilisateurs de visualiser les transcriptions à différents niveaux : mot, ligne, paragraphe ou page. Dans cette interface, l'élément pertinent de l'image est mis en évidence et la transcription est affichée dans un panneau détaillé. Ce panneau comprend le score de confiance, la source de la transcription (algorithme, modèle) et un lien vers le processus d'exécution qui a produit cette transcription. Arkindex est particulièrement bien adapté à l'exploration des résultats de la transcription, offrant une interface intuitive et informative permettant aux utilisateurs d'approfondir les détails du processus de transcription et ses résultats.
Callico pour l'évaluation et la validation : Callico est conçu pour les campagnes d'évaluation ou de validation dans lesquelles une équipe d'annotateurs évalue ou corrige les résultats d'une transcription automatique. Cet outil fournit un système complet de gestion des flux de travail pour traiter les campagnes de validation impliquant un grand nombre de documents et d'annotateurs. En plus de faciliter le processus de validation, Callico fournit également une évaluation du taux d'erreur de caractères (CER). Il permet également d'exporter toutes les transcriptions au format CSV ou XLSX pour une analyse statistique plus approfondie. Cela fait de Callico un outil précieux pour les équipes qui entreprennent une évaluation ou une correction systématique et à grande échelle des transcriptions automatisées.