

Reconstructing French history "from the ground up": a century of population censuses deciphered by the Socface project
This article was originally published in issue 144 of the journal Culture et Recherche, which focused on Open Science.
Authors :
- Lionel Kesztenbaum is Director of Research at the National Institute for Demographic Studies (INED)
- Manonmani Restif is the Project Manager for the FranceArchives portal at the Interministerial Archives Service of France (SIAF)
- Christopher Kermorvant is the President of the company Teklia
Introduction
Socface is a research project, supported by the French National Research Agency (ANR), on the censuses of the French population from 1836 to 1936. It mobilizes researchers in the humanities and social sciences, engineers and archivists, and illustrates many aspects of open science as well as the contributions and challenges of automatic handwritten text recognition (HTR, Handwritten Text Recognition).
Project objective
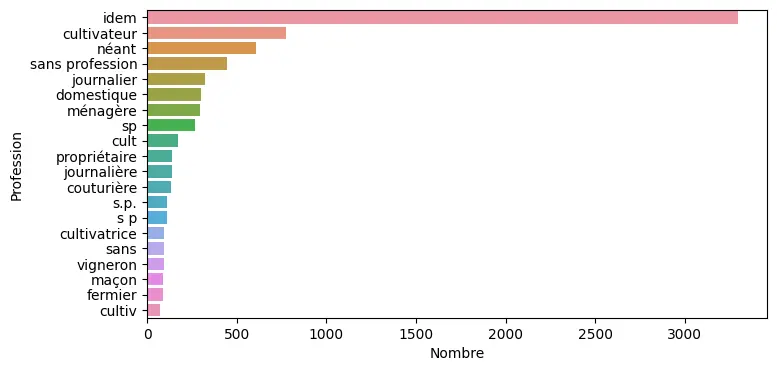
The Socface project aims to automatically transcribe all the nominal lists from the censuses of 1836 to 1936 (twenty censuses) in order to produce, study, and disseminate a database of individuals who lived in France during this period.Supported by the French National Research Agency (ANR), this project illustrates many aspects of open science as well as the contributions and challenges of automatic handwriting recognition.
Importance of personal data
It also highlights the ever-increasing appetite of various archive users for personal data: today, the vast majority of searches conducted in archive services focus on this type of source.Every person has a right to be represented in the archives, as soon as their life has included some events, whether happy or, more often, unhappy.
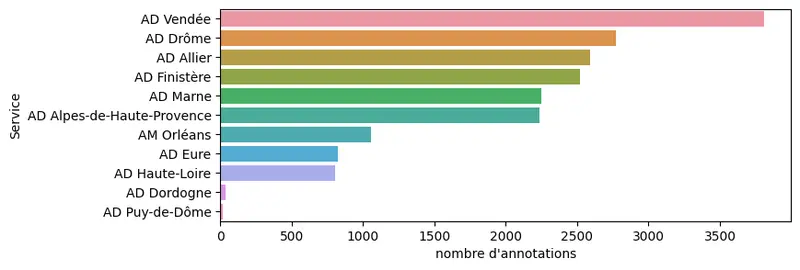
Socface deserves a special place because of its scope: it covers a very large corpus – the same typology, treated over 100 years, preserved in nearly 100 structures in metropolitan France and overseas.
The origins of the project
The growing interest in individual data, particularly personal data, is fueled by technical developments (ease of digitization, dissemination of images on the Web, improvements in automatic handwriting recognition techniques, etc.) as much as it feeds them: the demand from users (researchers, genealogists or informed amateurs) motivates digitization campaigns just as the appetite of quantitative research in social sciences for "micro" data stimulates the development of automatic handwriting recognition.
Virtuous circle of digitization
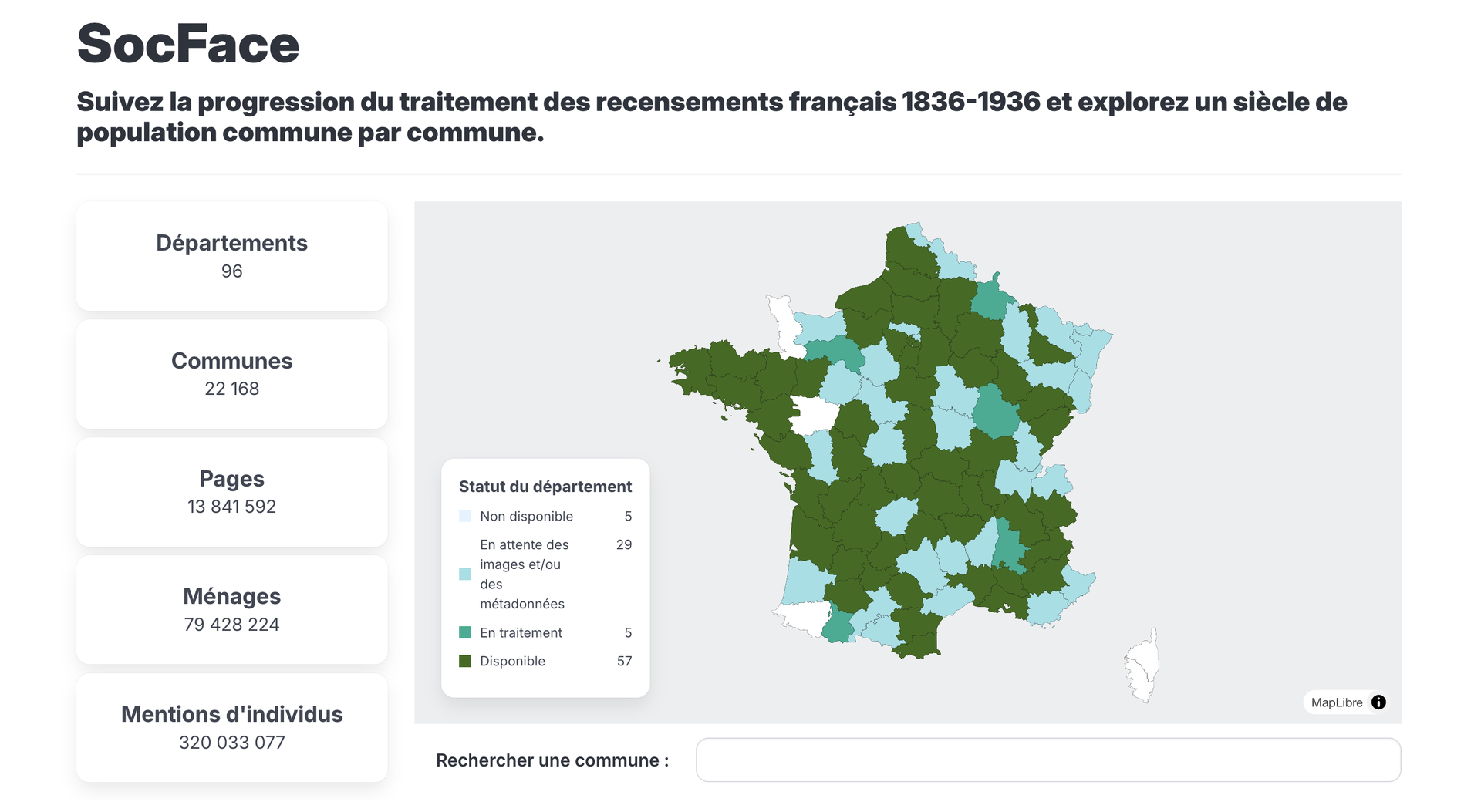
Socface perfectly illustrates this virtuous circle around a single source (censuses), which is one of the few types of documents to have been almost entirely digitized by archives services, creating a corpus that should eventually exceed 10 million images despite destruction, whether intentional or accidental. This near-exhaustive digitization was a prerequisite for such a research project to be carried out.
Text extraction
Once this condition was met, historians' appetite for this mass of data wasn't enough; an efficient system still needed to be devised to extract the text contained within these millions of images. The considerable progress in automatic handwriting recognition in recent years, thanks to advances in artificial intelligence technologies, makes this extraction possible.Historical handwritten documents, from the Middle Ages to the present day, are now amenable to automatic transcription, allowing for direct use. This automatic recognition is particularly valuable for very large-scale processing where manual transcription, even collaborative, is not feasible.
The role of collaboration in handwriting recognition
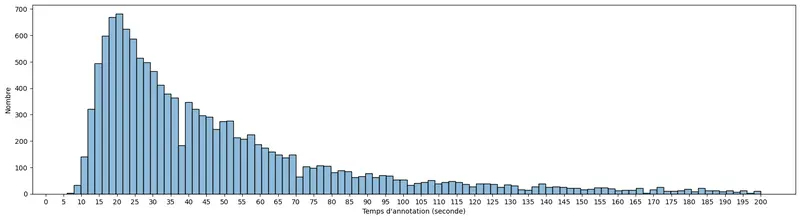
However, handwriting recognition is not a self-contained, entirely autonomous process. Developing a high-performing handwriting recognition system requires a training phase for models on annotated data, using supervised machine learning techniques. The latest models, based on deep learning technologies, can be trained with a much simpler protocol than their predecessors. Today, it is no longer necessary to precisely transcribe documents, indicating the position and content of lines of text.It is possible to train models using data entered into a form, much like one would for archival research. This much faster and more natural protocol allows for the use of volunteers to create the annotations.
The Socface project has thus launched around ten collaborative annotation campaigns to create training data using Teklia’s Callico platform.
Using existing annotations
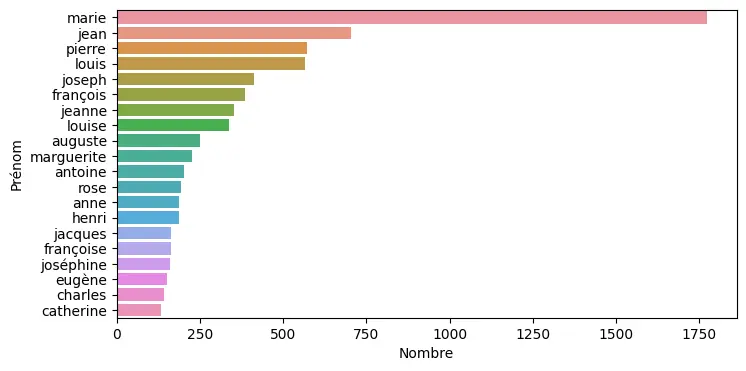
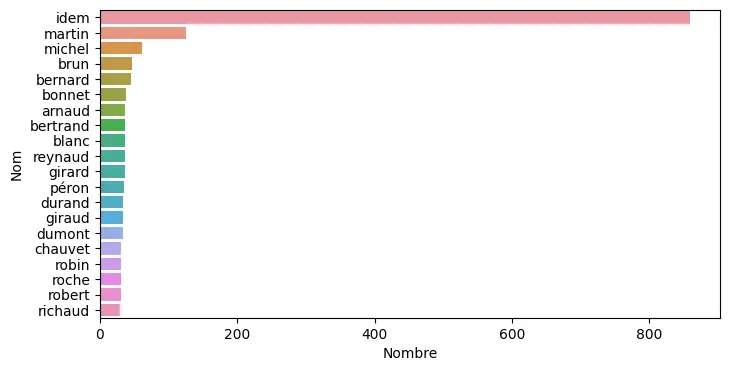
Furthermore, existing annotations, made by genealogical societies or in departmental archives, can also be used to train the machine.In fact, the quality of recognition is improved by a whole range of external information: from the list of surnames (and their frequency) to the names of localities in each municipality, including a rough estimate of age distributions over time, anything that can give the machine an idea, however vague, of the "universe of possibilities" is valuable.
In this sense, Socface is very directly a product of open science.
Processing, analyzing and distributing millions of images
The century of French history studied by Socface is marked by dramatic changes often summarized by a few broadly outlined concepts: urbanization, industrialization, and demographic transition.However, the spatial variation of these phenomena across metropolitan France, their mechanisms, and their consequences remain relatively poorly understood.Socface's contribution, particularly in matching individuals across censuses to reconstruct their life trajectories (migratory, professional, and familial), is to enable the study of this heterogeneity, to grasp how these trajectories intersect, or do not intersect, with "Grand History," how they are influenced by it, and how they, in turn, influence it.
Data dissemination
A second direct outcome of the project will be the free dissemination of this data, making it accessible to everyone.For archives, this availability of a large volume of data, both in the FranceArchives name database and on the websites of archival services, represents a tremendous opportunity to develop new services for their users interested in individual microhistory.It also opens up possibilities for pooling resources within the archival network to increase the stock of interoperable archival metadata.
Future impact of Socface
Ultimately, Socface will have a tremendous multiplier effect.On the one hand, it will inevitably encourage the digitization of missing censuses, and even their identification.On the other hand, it can provide a foundation for implementing other large-scale source analysis projects.More broadly, it should foster collaboration between archivists and the research community, with the former able to re-evaluate their digitization policies, for example by developing a national approach around comprehensive typologies, while the latter will need to be more diligent in sharing the data it produces with archival services.